Identification of data needs for Dispatcher3

Author: Damir Valput (Innaxis)
The main objective of Dispatcher3 is to leverage historical data and machine learning techniques to support flight management activities prior to departure, as described in our first blog post. The airline dispatchers assist in flight planning of individual operations considering different data sources such as weather forecast, restrictions in airspace usage and airport conditions. Unlike in the North American market however, in Europe the role of dispatcher is highly automatised with most of the effort being dedicated to the supervision of the dispatching activities, and the usage of common flight plan generators such as Lufthansa LIDO software is wide-spread.
Nevertheless, the dispatching process understood as the management of the fleet on the day of operation has increased the relevance decision making process with a longer lookahead. Identifying potential disruptions early in the day might provide possibilities to plan for solutions beyond adjustment of flight plans (e.g., aircraft swapping). Finally, independently of the automation, dispatchers preparing the flight plans might still manually intervene to adjust and modify solutions when non-nominal situations arise.
For Dispatcher3 as a data-driven project which aims at reducing uncertainties in airlines’ flight management and planning processes, creating a solid and comprehensive data collection and management plan is key. It is often said that in machine learning projects 80% of effort and success can be attributed to data collection and preparation, and for those reasons we adapted a very data-centric workflow in Dispatcher3.
Starting with the feedback obtained from the Advisory Board, we identified several groups of users which could benefit from a prototype such as Dispatcher3 and we attributed a number of target variables we wish to estimate from historical data. Additionally, each target variable comes with a forecasting horizon at which a forecast of that variable should be provided, ranging from 0.5 hour before the flight (H-0.5) to 1 day prior to the flight (D-1). As an example of identified targets we identified a reactionary delay estimator to be of interest for duty managers with a forecasting horizon of 3 hours before the flight, or a fuel deviation estimator which we of potential use for dispatchers (with the same forecasting horizon). For a full list of identified target variables as part of Dispatcher3 data management plan, take a look at the right hand side of Figure 1 (in green).
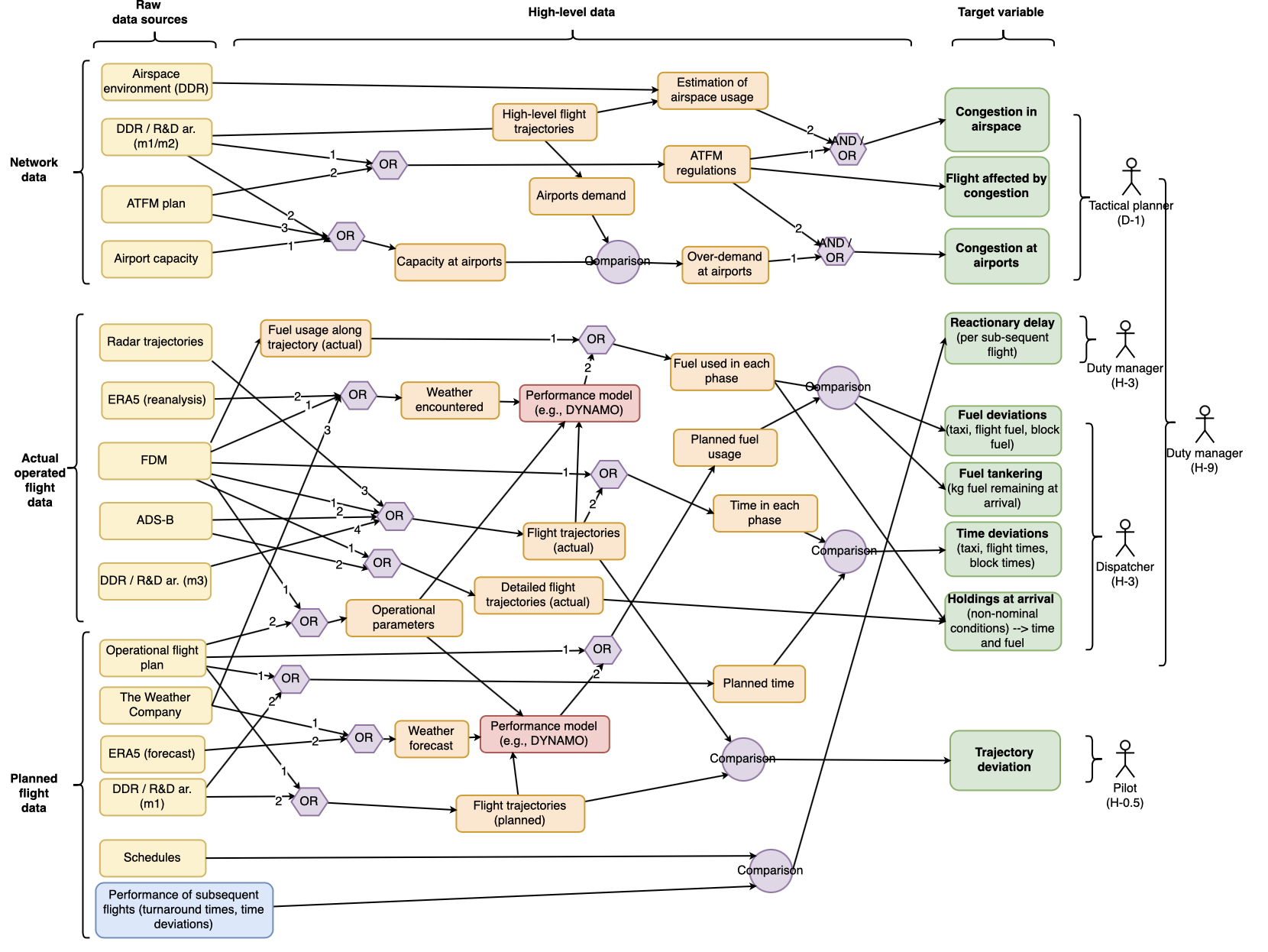
Figure 1. Data management plan in Dispatcher3, general schema: from raw data sources to target indicators
Subsequently, we identified possible predictors that could be influencing the targeted indicators we aim at forecasting, and thus should be considered for the feature engineering block of the machine learning pipeline. Additionally, having in mind the forecasting horizons, we identify a number of data sources which can be used to compute or estimate those features, and which are available to us or we reasonably expect to be able to obtain them. This identification resulted in a product we call data catalogue which lists all the data sources we wish to consider in Dispatcher3 sorted by different data categories (e.g. network data or operated flight data), along with possible providers of those data sources. The general schema of that catalogue is shown on the left hand side of the diagram on Figure 1, with raw data sources in yellow boxes.
Groups of features we plan to engineer as part of machine learning development, as shown in the centre (orange) part of the diagram, have been assigned to all the data sources from which they could be produced. Naturally, one group of features such as for example “weather forecast features” could be engineered from more than one raw data set, which is indicated by the numbers on the arrows connecting feature groups and raw data sources. This served as a basis for creating data collection plan in which the data sets within the data catalogue have been prioritised accordingly, considering the relevance for the models we wish to develop in the project.
This minutious data management plan will help us not only to plan and execute our data collection and model development more efficiently, but to react in a very agile way in case a certain data source proves to be unavailable for whatever reason and we need to modify our plan, something that happens fairly often in machine learning projects. It also enables us to shift the focus of the project from a more model-centric to data-centric approach, treating the data as the primary asset of a machine learning project which is showing to be a key for a more successful excution. Moreover, this serves as a great input for definition of case studies and development plan which we are currently working on. The case studies will allow us to define the scope required for the data acquisition because they will focus on specific routes, indicators and forecasting time frames, for which definition and prioritisation the feedback from the Advisory Board and stakeholders will be taken into account.