The particularities of Verification and Validation for Machine Learning data driven projects

Authors:Jovana Kuljanin & Julia de Homdedeu (UPC)
How does verification and validation approach in machine learning differ from the canonical verification and validation approach?
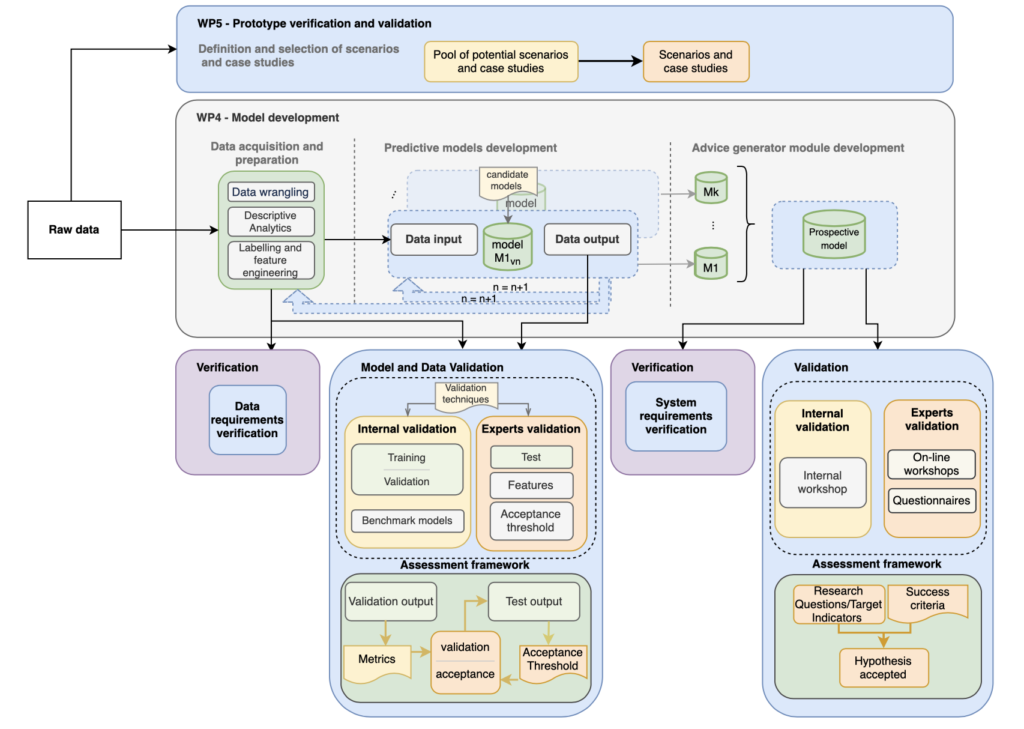
Dispatcher3 is a data-driven project which requires a distinctive approach in the verification and validation. Unlike traditional software development methodologies which typically follow the principal of the canonical verification and validation approach, the lines between development and verification and validation remain very often blur in the domain of the machine learning. This means that the different activities involving data collection, data preparation, development and verification and validation are very inter-related, and an iterative “design-train-test-validate” process with a lot of back and forth between different experts is crucial for maximising the success of Dispatcher3.
The core of the verification and validation approach is structured around three different and inter-related phases, which have to be combined iteratively and in close coordination with the experts from the consortium and the Advisory Board, namely:
- Data acquisition and preparation – the verification and validation activities within this phase need to ensure that the process of data preparation is executed properly in order to obtain a data set of a satisfiable quality for training specific machine learning algorithms. The verification activities need to ensure that the data requirements are properly met, while validation activities will be performed to make sure that the labelling and feature engineering activities are properly driven by the experts’ input and user requirements.
- Predictive model development – standard validation activities in a machine learning pipeline will be performed to make sure the model performs well (accuracy) and according to the expectations. That means that for each machine learning model that is going to be developed a reference level of accuracy or a benchmark model needs to be established as a part internal validation. Naturally, a set of standard metrics commonly used in machine learning will be used in Dispatcher3 as well to evaluate the model results. The output of the predictive models will also be assessed by the experts to see if the development is moving in the “right direction” as a part of the validation activities performed with experts.
- Advisory generator model development – the last phase encompasses verification and validation activities that will be conducted using fully developed prototype that will, relying on the predictive models output, present a series of advice for targeted users of a particular model/case study. Similar to the machine learning model development, the Advice Generator will be developed in an iterative manner and will be based on the outcome of the machine learning model. Therefore, the industrial partner within the consortium, Vueling, skeyes and PACE, will be mainly involved in assessing the benefits of the advice generated, as the latter will be tailored based on the outcome of the ML models that use their data.
Is the definition of case study also data-driven?
When defining a case study in the domain of machine learning, one needs to make sure that it captures the problem or a questions that can be effectively answered by some predictive model and the historical datasets available at hand, i.e., one predictive model essentially learns one mapping between the input (features) and the output (label, targeted indicator) and a case study should be defined in such a way that we can expect a predictive model to be able to learn from the given data (e.g., for routes between a given origin-destination pairs or for flights arriving at a specific airport).
Concretely, a particular case study in Dispatcher3 might have to focus on one concrete route since a lot of the datasets we will be working with is route-dependent and the function that a trained model learned most likely would not perform well if the same trained model was tried to be used on a different route (due to the concept known as “data drift“).
How the case study will be eventually structured?
In order to structure all these different considerations mentioned above, the definition of case study will highly depend on two different elements, namely:
-
- routes of interest – all the ML models developed within the project will be route-based. However, the experts within the consortium (i.e., Vueling) may show a particular interest on the specific route which is worth analysing from the operational point of view.
- prediction horizons – for the given route and specified targeted indicators, different model outputs can be obtained at different time-frames. Therefore, these predictions-horizons should be considered when collecting the datasets that will be used to characterise the available information at the given time-frame. This means that the same dataset might be required at different time-horizons with different resolution. The predictions at different time-frames will tackle different targeted indicators and roles involved in flight management process.